Is CQRS too complicated? No!
How do you feel after reading a few articles about CQRS (Command Query Responsibility Segregation)? Confused?!
The good news is that's not your problem.
CQRS is a simple concept, but usually is presented side by side with other patterns creating the perception that CQRS requires a ton of elements to work.
This post pretends to demonstrate that CQRS can be a simple concept that can evolve according to your needs.
So, what is CQRS?
The roots of CQRS are based on Command-query separation (CQS) a principle created by Bertrand Meyer during the development of Eiffel programming language.
Meyer states that "Asking a question should not change the answer" and that's the foundation of CQRS.
We can conclude from that statement that a command is any method that creates, update or delete data, and a query is any method that returns data.
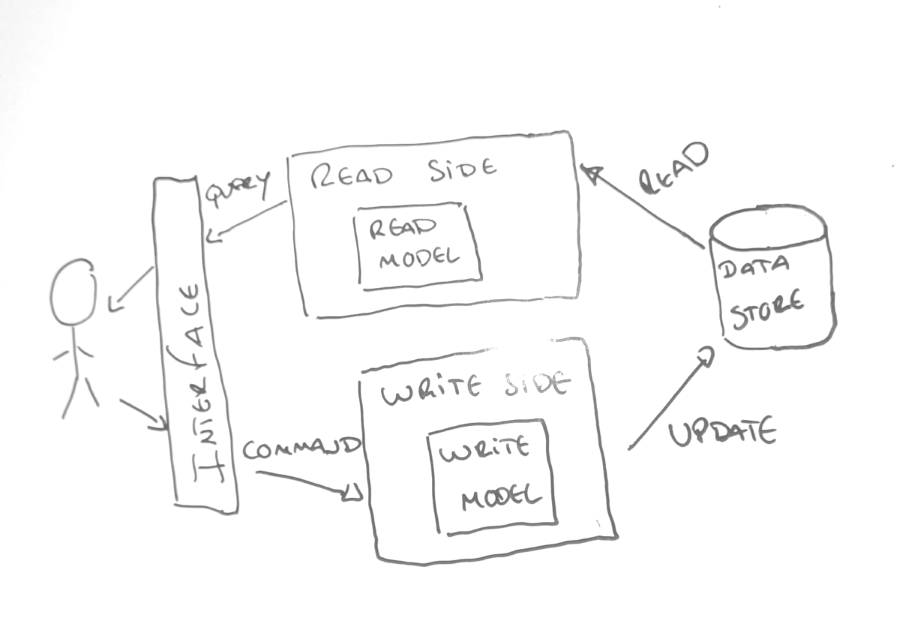
CQRS is an evolution of CQS, going further with the initial concept and stating that Read and Write models should be distinct.
CQRS is simply that, is the segregation of two main responsibilities, the responsibility of read data and the responsibility of mutate data.
Don't you recognize this principles? "Denormalization", cache systems, read-optimized databases and others, are proof that the industry is already thinking in the problems CQRS want's to solve.
It's important to say that there's nothing in CQRS saying that we should use Event Sourcing, Service Bus or another element to implement CQRS. Those patterns or technologies are usually presented with CQRS, adding a new layer of complexity to CQRS.
Nothing about CQRS says “you shalt use NServiceBus”. It’s just not there. You’re merely separating infrastructure between handling commands and queries, but the how is quite varied.
CQRS Benefits
*All the following benefits are capabilities that CQRS gives you, but they aren't required to implement CQRS*
Simple Queries
Because the Read model is different from the Write model, it's possible to create simpler queries and with better performance. If the Read and the Write model are shared, you will constrain the Queries to the Write structure.
The system will also benefit of a thinner Read layer.
Simple code is fast code
Separate data store
Since the Read model is separate, you are able to segregate the database, querying a non relational database optimized for queries.
That will lead us to concepts like Eventual Consistency or Event Sourcing, but it's important to say that CQRS doesn't require this, he just enables the capability.
It's perfectly possible to implement CQRS using the same data store.
Event sourcing is a completely orthogonal concept to CQRS. While they fit well together, doing CQRS does not require event sourcing, and doing event sourcing does not automatically mean we’re doing CQRS.
Queued workload
Commands can be processed using a queue, enabling an asynchronous command processing, what can be useful to deal with complex processing or manage the system load.
Segregate load
Typically the number of queries in a system is much higher than the number of commands. So, why should both be based on the same technologies?
CQRS enables the segregation of the Load, with the possibility of use a different host for each part of system.
The largest possible benefit though is that it recognizes that their are different architectural properties when dealing with commands and queries … for example it allows us to host the two services differently eg: we can host the read service on 25 servers and the write service on two
Challenges
CQRS isn't just benefits. CQRS implies complexity and a new mindset when using it.
Usually we are formatted to think in CRUD operations, but with CQRS we're led to a Task-based system. We need to rethink the UI to be based on tasks and to deal with the eventual consistency (if we need it).
I can't say that CQRS fits all the cases or is a tool that you should use always. What I can say is that's an important tool to have in mind when dealing with some complex problems.
It's important to remember that you should start simple and CQRS enables you to adjust and evolve if you need it.
Don't try to do all upfront.